Why CISC?
(Complex Instruction Set Computer)In the days of the Eniac (1943, John Mauchly and J. Presper Eckert), the U. S. Army wished to have a mechanical computing engine to replace the human computing engines currently used to produce ballastics charts for cannons. Computer time was scarce and people time was available. Assembly language programming was the only higher level language available and powerful instructions would benefit the human programmers.
- Space and Time
The CPU clock refers to the synchronization of instructions, think of this as a drummer keeping time for a marching band. As each "click of the clock" an action is completed. Suppose you have a 12.5 ns clock (ns = nanosecond = 10^-9 second). How many instructions will complete in one second?
1/12.5*10^-9 = 0.08 * 10^9 = 80 * 10^6 = 80 MHz
A Hertz is the unit of frequency equal to one cycle per second. - Beliefs about Complex Instruction Sets
They were right for the early days (1950's, 60's, 70's?).
Note: Knuth's fundamental paper on LR parsing for compilers appeared in 1968.
Fundamentals of RISC
Characterizing RISC
-
- Instruction Pipelining - Subdivide an operation into equal
amounts of work (analagous to the assembly line for auto manufacturing).

Fig2.1 a Pipeline
© O'Reilly Publishers (Used with permission)- Variable length instructions pose questions, such as
- how many bytes the instruction uses?;
- what type of instruction is it?;
- where do the operands come from?
- where does the result go?
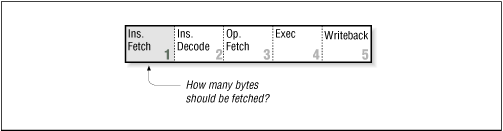
Fig2.4 Variable length instructions make pipelining difficult
© O'Reilly Publishers (Used with permission)- Stages of 3 pipelined instruction sequences, in time
- Variable length instructions pose questions, such as
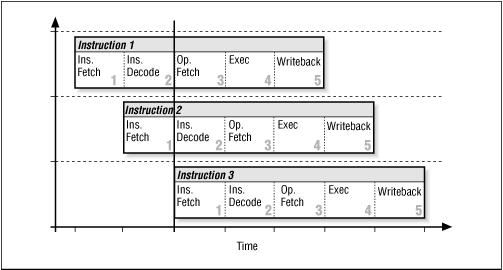
Fig. 2.2 Thres instructions in flight throuigh pipeline
© O'Reilly Publishers (Used with permission) - Instruction Pipelining - Subdivide an operation into equal
amounts of work (analagous to the assembly line for auto manufacturing).
{kind=link}
Variable length versus Fixed length
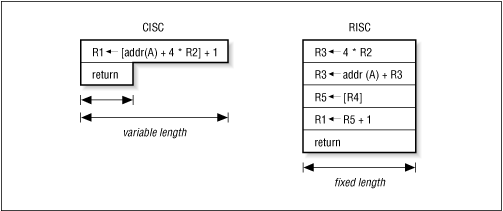
Fig 2.5 Variable-length CISC versus Fixed length RISC instructions Note typo: Second R3 should be R4
© O'Reilly Publishers
(Used with permission)
Detailed example from instructor
Expanded example Fig. 2-5
Note: Our goal is to interact effectively with the compiler,
which is charged with generating efficient assembly language when
translating our high level language programs in C or Fortran 90.
You are invited to examine the wealth of options available to you
for interacting with the compiler, using the Unix command
man cc | more
or wait for our lab and explorations.
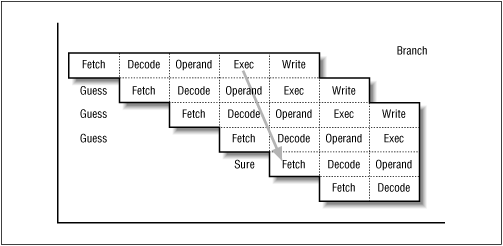
Fig 2.3 Detecting a branch
© O'Reilly Publishers
(Used with permission)
A delayed branch instruction would interrupt the "pipeline" and
might delay all the processing of the following instructions.
- Uniform length instructions impose this budget of bits
- Reduce decoding of what instruction will accomplish
- Load/store from memory typically take much longer than arithmetic
Second-Generation RISC Processors
Three basic methods:
- Make clock rate faster - design technique for DEC Alpha processors
- Duplicate compute elements with freed-up chips space (Superscalar)
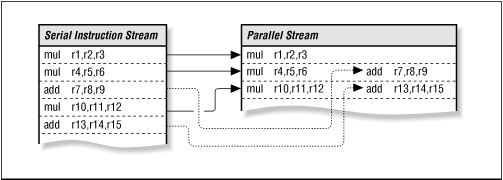
Fig 2.6 Decomposing a serial stream
© O'Reilly Publishers (Used with permission) - Increase number of stages in the pipeline
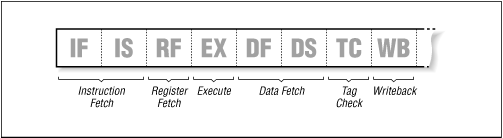
Fig 2.7 MIPS R4000 instruction pipeline
© O'Reilly Publishers (Used with permission)