
© O'Reilly Publishers (Used with permission)
Recall, the Bus Architecture of the PC

© O'Reilly Publishers (Used with permission)
as well as the concept of the Crossbar, quite expensive, which are discussed in Chapter 10.

© O'Reilly Publishers (Used with permission)
Fig. 12-2: Connecting processors to memory

© O'Reilly Publishers (Used with permission)
Processors will be wired to use the interconnect to communicate with other processors and to communicate with memory.
Fig. 12-3: Connecting nodes to one another

© O'Reilly Publishers (Used with permission)
Processors can also have their own local memory and the ability to communicate with other processors and their individual local memory.
Fig. 12-4: Pipelined multistage interconnection

© O'Reilly Publishers (Used with permission)
Fig. 12-5: Multistage interconnection network

© O'Reilly Publishers (Used with permission)
Fig. 12-10: Flynn's taxonomy
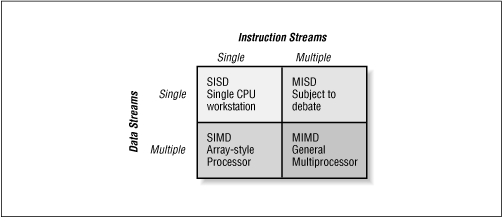
© O'Reilly Publishers (Used with permission)
Table 12.1 Features of Shared Uniformed Memory Systems ------------------------------------------------------------------ System |Processor | Max CPUs | Memory Bandwidth ------------------------------------------------------------------ SGI Power | MIPS-R1000 | 36 | 1.2 GB/sec (bus) Challenge | | | DEC 8400 | Alpha-21164q | 14 | 1.8 GB/sec (bus) Sun E6000 | UltraSparc-2 | 30 | 2.5 GB/sec (bus) Sun E10000 | UltraSparc-2 | 64 | 13 GB/sec (crossbar) *** Note: SDSU has an E10000 - what do you think it is used for? **** HP Exemplar | PA-8000 | 16 | 15 GB/sec (crossbar) Cray T90 | Cray Vector | 32 | 800 GB/sec (crossbar
Fig. 12-12: Architecture versus time: top 500 report

© O'Reilly Publishers (Used with permission)
Top 500 online Where is SDSC?